Optimiser le Cache Navigateur avec No-Vary-Search


Sciemment ou non, vous utilisez certainement des paramètres d’ URL Une URL (Uniform Resource Locator) est l'adresse unique d'une ressource sur Internet, comme une page web, une image ou un fichier, permettant de la localiser et d'y accéder via un navigateur. . Cela peut être des codes de tracking UTM ajoutés par vos campagnes marketing, des paramètres publicitaires, ou de simples identifiants de session. Ces petits ajouts à vos URLs semblent inoffensifs. Pourtant, ils ont un impact significatif sur les performances web en empêchant d’optimiser le cache Le cache est un espace de stockage temporaire qui conserve des données fréquemment utilisées pour accélérer leur accès ultérieur, réduisant ainsi les temps de chargement et la consommation de ressources. navigateur : chaque variation de paramètre force une nouvelle requête Le HTTP (HyperText Transfer Protocol) est un protocole utilisé pour transférer des données sur le web, permettant la communication entre un navigateur et un serveur pour afficher des pages web. au lieu d’utiliser la page déjà en cache !
Toutefois, le web n’étant pas sans inventivité, un nouvel entête HTTP Une entête HTTP est un ensemble de champs d'information échangés entre un client (navigateur) et un serveur lors d'une requête ou réponse. Elle contient des données comme le type de contenu, les cookies ou les méthodes d'authentification. disponible dans Chrome est en passe de devenir une solution standardisée pour optimiser le cache navigateur et pallier au problème. Revenons au sein de cet article sur cette petite révolution qui pourrait économiser d’énormes quantités de bande passante et améliorer considérablement l’ expérience utilisateur L'expérience utilisateur (UX) désigne la qualité de l'interaction d'un utilisateur avec un produit ou service, en termes de satisfaction, facilité d'utilisation et efficacité. .
Description du problème
Imaginez qu’un utilisateur visite votre page d’accueil via un lien contenant ?utm_source=email. Puis, en cliquant sur votre logo, il y retourne quelques minutes plus tard. Techniquement, il s’agit de la même page avec le même contenu. Mais pour le navigateur et les systèmes de cache, ce sont deux URLs différentes. Donc le navigateur effectuera une nouvelle requête plutôt que de profiter du cache de la première requête.
Et maintenant imaginez cela à l’échelle de votre site avec ces 1000, 10 000 ou 100 000 pages vues par mois grâce à des liens partagés dans des mails ou des réseaux sociaux… Combien de requêtes inutiles effectuées cela représente à l’échelle du web ? On est en droit de penser que l’efficience n’est pas au rendez-vous de la transition écologique que nous souhaitons tous. Mais au delà de cela, l’expérience utilisateur en pâtit elle aussi, car une requête sera toujours moins rapide qu’une page issue du cache navigateur. Enfin, sur des sites à fort trafic, je ne vous parle pas du coût.
Et le problème peut devenir autrement plus grave.
Sur votre blog hébergé sur un serveur modeste, grâce à vos talents d’écriture (nettement plus évolué qu’une IA, j’en suis certain), votre prose devient virale et un article se propage de manière exponentielle sur les réseaux sociaux. Chaque lien vers cet article fait par ces différentes sources ajoute ses propres paramètres UTM différents. Or comme nous l’avons vu, le cache navigateur n’est pas utilisé dans ce cas précis. Il y a fort à parier que le modeste serveur ne puisse servir tout le monde et voire même tomber en rade !
C’est la même chose pour un site e-commerce qui, en période de solde, se retrouve avec un trafic monstre depuis des sources avec chacune avec ses propres paramètres de tracking et d’affiliation. Malgré des serveurs puissants et la présence d’un CDN Un CDN (Content Delivery Network) est un réseau de serveurs répartis dans plusieurs emplacements géographiques qui distribue du contenu web de manière plus rapide et efficace en rapprochant les ressources des utilisateurs finaux. , ces paramètres contournent le cache. Et là c’est la cata : le site s’effondre.
Le péché originel
Selon les spécifications du W3C Le World Wide Web Consortium (W3C) est une organisation internationale qui développe des standards ouverts pour assurer la croissance à long terme du web, comme HTML, CSS, et XML. et de l’IETF (qui définissent les standards web), les paramètres d’URL devaient originellement servir à :
- Identifier une ressource et modifier son contenu.
D’après la RFC 3986, le composant query (les paramètres après le ?) contient des données non-hiérarchiques qui, avec le chemin, servent à identifier une ressource dans le cadre du schéma de l’URI. - Exprimer une requête sur un objet.
La spécification W3C originale indique que le point d’interrogation est utilisé pour délimiter la frontière entre l’URI d’un objet interrogeable et un ensemble de mots utilisés pour exprimer une requête sur cet objet. - Transmettre le contenu de formulaires
HTML
Le HTML (HyperText Markup Language) est le langage standard utilisé pour structurer et afficher le contenu sur le web. Il définit des éléments comme les titres, paragraphes, liens, images, et autres composants d'une page web.
.
Une des utilisations originelles était de contenir le contenu d’un formulaire HTML, où les paires champ-valeur sont encodées dans la query string. - Et donc permettre au serveur de modifier sa réponse.
Les serveurs web peuvent utiliser ces paramètres pour modifier les réponses, comme appliquer un filtrage, une recherche ou un tri des résultats.
En résumé : les paramètres d’URL étaient conçus comme un mécanisme côté serveur pour passer des données qui modifient le contenu de la réponse. L’usage pour le tracking côté client (UTM, etc.) détourne l’objectif imaginé par la spécification, d’où les problèmes de cache décrits ci-dessus !
Or, il existe de très nombreux services de suivi côté client. Des paramètres UTM issus de l’analyse aux paramètres de suivi publicitaire, ces derniers sont lus par le code JavaScript JavaScript est un langage de programmation dynamique principalement utilisé pour ajouter des fonctionnalités interactives aux pages web. Il permet de manipuler le DOM, de gérer des événements, et d'effectuer des requêtes asynchrones. chargé sur la page ou servent à enregistrer et/ou mesurer des données nécessaires (qui sont parfois même personnelles). Le plugin W3TotalCache en référence une centaine dans sa configuration par défaut !
Le cache côté serveur à la rescousse
Heureusement de nombreux CDN ou plugins de cache, vous permettent d’ignorer les paramètres de requête et servir le même contenu depuis leur cache côté serveur, plutôt que de solliciter votre serveur d’origine ou la base de données. Mais attention, ce n’est pas toujours le comportement par défaut, cela nécessite une configuration
Vous pouvez ignorer tous les paramètres de requête (simple, mais probablement risqué si votre application en a besoin), ceux couramment utilisés ou des règles plus complexes. Tout cela est personnalisé et non standardisé. Par exemple, WP-Rocket, célèbre plugin de cache pour WordPress WordPress est un système de gestion de contenu (CMS) open-source qui permet de créer et gérer facilement des sites web, des blogs et des boutiques en ligne sans compétences en programmation. , ignore tous les paramètres d’URLs sauf ceux définis dans Paramètres avancés > Cacher les Query String(s).
Toutefois, cela n’économise pas la requête. Le navigateur continue d’interroger le serveur avec ou sans CDN pour une récupérer une page identique entre une URL avec paramètres et la même URL sans. De plus, chaque requête sera stockée de manière distincte dans le cache du navigateur encombrant ainsi l’espace mémoire dédié au site avec deux pages identiques.
Un nouvel entête HTTP : No-Vary-Search
Cette fonctionnalité est née des travaux de Chrome sur les speculation rules, où il fallait pouvoir reconnaître que deux URL apparemment distinctes pointaient vers le même contenu. Mais son utilité dépassait largement ce cas d’usage initial : elle a donc été élargie et proposée à l’IETF pour devenir un standard HTTP.
A ce jour (janvier 2026), seule la sphère Google supporte ce nouvel entête, mais il est déjà en preview chez Safari. Aucun inconvénient à l’ajouter dès maintenant : les navigateurs qui ne le comprennent pas l’ignorent simplement.
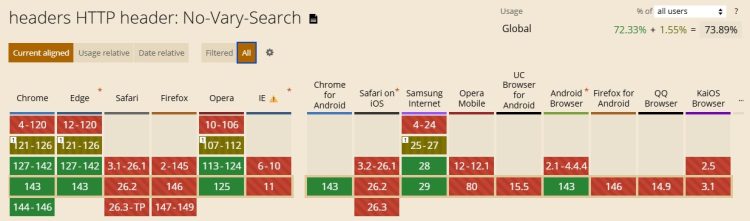
No-Vary-Search est donc un en-tête HTTP que le serveur envoie pour indiquer quels paramètres d’URL peuvent être ignorés lors de la mise en cache par le navigateur.
Il y a 4 directives possibles :
- key-order : signifier que l’ordre des paramètres n’a pas d’importance.
No-Vary-Search: key-order
Ces deux URLs sont considérées comme identiques :
https://example.com/?param1=1¶m2=5
https://example.com/?param2=5¶m1=1 - params : ignorer TOUS les paramètres
No-Vary-Search: params
Toutes ces URLs sont traitées comme identiques :
https://example.com
https://example.com/?utm_source=email
https://example.com/?utm_campaign=winter2025 - params=(« liste ») : ignorer les paramètres définis dans la liste.
No-Vary-Search: params=("utm_campaign" "utm_source")
Effet : Ces URLs sont identiques :
https://example.com
https://example.com/?utm_source=email
https://example.com/?utm_campaign=winter2025
Mais celle-ci serait différente :
https://example.com/?autre_param=valeur - params, except=(« liste ») : ignorer tous les paramètres SAUF certains
No-Vary-Search: params, except=("q" "productid")
Effet : Toutes ces URLs sont identiques :
https://example.com/?productid=1234
https://example.com/?productid=1234&utm_source=email
https://example.com/?utm_source=email&productid=1234
https://example.com/?productid=1234&tracking=xyz123
Mais celles-ci seraient différentes :
https://example.com/?productid=5678 (productid différent)
https://example.com/?q=search (q est protégé)
Cas pratique pour optimiser le cache navigateur
Vous pouvez utiliser cette configuration pour la plupart des sites et donc réduire les requêtes HTTP inutiles :
No-Vary-Search: key-order, params=("utm_source" "utm_medium" "utm_campaign" "utm_term" "utm_content" "gclid" "fbclid" "msclkid" "srsltid")
Cette configuration :
- Ignore l’ordre des paramètres
- Ignore tous les paramètres de tracking courants
- Garde tous les autres paramètres significatifs
Comment ça marche en pratique ?
- Le serveur envoie la page avec l’en-tête
HTTP/2 200 OK
No-Vary-Search: key-order, params=("utm_source" ...
Content-Type: text/html - Le navigateur met en cache la page avec l’URL visitée : example.com/?utm_source=email
Stocké en cache avec la règle : « ignorer utm_source » - L’utilisateur visite une variante avec une nouvelle URL : example.com/?utm_source=linkedin
- Le navigateur consulte son cache
- Il trouve la page précédente
- Il applique la règle No-Vary-Search
- Il constate que seul utm_source diffère
- Il sert la page depuis le cache au lieu de la re-télécharger !
Optimiser le cache navigateur dès maintenant !
A l’instar de Barry Pollard qui m’a fait découvrir cette nouveauté, je pense qu’il faut se réjouir. Le No-Vary-Search est exactement le genre d’innovation simple que j’adore. Cette nouveauté simple à implémenter dès 2026 a un impact potentiellement énorme sur les performances globales. Mais là c’est surtout l’impact global en matière d’écoconception qui m’enthousiasme. Au vu du nombre pharaonique de lien de partage, de liens dans des newsletter et j’en passe, c’est un potentiel énorme de requêtes en moins sur la toile. Et on peut aussi en attendre une consommation d’énergie réduite à tout niveau (sur l’appareil de l’utilisateur, sur l’infrastructure réseau et enfin les serveurs).
Comme expliqué ci-dessus, vous n’avez besoin de convaincre personne : il ne s’agit pas de refondre complètement votre site. En cinq minutes de configuration et quelques tests, votre site devient immédiatement plus efficient pour des millions d’utilisateurs Chrome et pour le bien de la planète.
L’adoption par Firefox et Safari n’est qu’une question de temps. L’intégration native dans les CDN suivra. En implémentant No-Vary-Search aujourd’hui, vous ne prenez pas de risque. Au contraire, vous prenez de l’avance. Et ces mois d’optimisation accumulés feront toute la différence.
Le web performant commence par des petites victoires. No-Vary-Search en est la première de cette année qui commence !


